Fraud Detection AI Agents: 6 Guardrails for Insurers

Editor’s note: Vadim discusses a fraud detection AI agent blueprint by ScienceSoft, first presented at the Insurance Transformation Summit 2025 in Boston. He shows how multi-agent orchestration with explicit guardrails keeps agentic investigation workflows safe, controllable, and compliant. He also addresses practical questions raised by U.S. insurance leaders at the event. If you want to discuss feasible agent launch paths for your organization, Vadim and other AI engineering consultants at ScienceSoft are ready to assist.
Across the insurance industry, nobody questions whether agentic AI works anymore. The gains in accuracy and efficiency are already visible in pilot programs, and the technology is maturing fast. What keeps carriers cautious is how AI agents behave once deployed into real operations. Recent surveys highlight the paradox: over 80% of insurers are exploring or already piloting agentic AI, but only 4% say they fully trust agentic workflows.
I heard the same sentiment at the Insurance Transformation Summit. Every executive I spoke with agreed that agentic AI represents the biggest leap forward in fraud detection in the decade. Yet every one of them also pointed to new risks that emerge the moment agents touch real systems. The main concerns were about the transparency of agent decisions, data privacy, accountability across agentic workflows, and interoperability with legacy claims platforms.
For those of us engineering fraud detection AI, this sets clear guidelines: agentic solutions should plug smoothly into insurers’ systems, behave predictably under governance rules, and show the rationale behind every decision. The goal is to create auditable, safety-first assistants that scale investigative capacity without breaking internal and regulatory controls.
Six Critical Safeguards for Agentic Insurance Fraud Detection
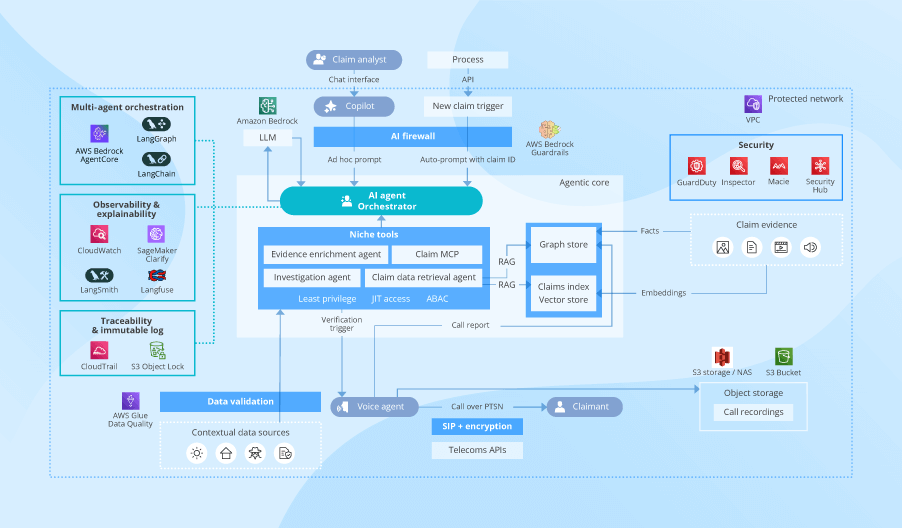
Below is the architecture scheme I demonstrated at the event. For this page, I expanded the blueprint with explicit agentic AI guardrails and technology options. These help insurers constrain what agents are allowed to do, make agent action explainable and replayable, and secure data and the agentic solution so nothing leaks, drifts, or exposes insurance systems.
Separation of agent duties
Just like human investigators, AI agents operate most safely and can be controlled best when they have a narrow scope of tasks and limited data access. A smart move for insurance is to employ several niche agents, each responsible for a single fraud detection task (identity checks, evidence review, and so on). Technically, this means each agent receives its own short-lived credentials and only the permissions its task requires. For example, a document intake agent can read invoices but cannot pull prior-loss history, and a network analysis agent can query graph relationships but cannot view PII.
ScienceSoft’s AI engineers enforce agentic duty boundaries via attribute-based access control by insurance line, data type, and regulatory class. Applying automated redaction of prompt contexts ensures the algorithms behind an agent never see more than they need to perform the task. Such an approach is naturally compatible with regulators’ requirements for data minimization.
Rule-based and “human‑in‑the‑loop” controls
Large language models (LLMs) are considered the “brain” of agentic fraud detection software. But all the operational heavy lifting is handled by the orchestrator, an engine that breaks the investigation into steps, assigns each step to the right agent, and controls what gets written into insurance systems. The orchestrator should also allow insurers to enforce rule-based guardrails for agentic workflows and to auto-trigger human approvals for high-risk actions.
At ScienceSoft, we rely on serverless orchestrators from major cloud agentic services like Amazon Bedrock AgentCore and Azure AI Foundry. Their toolsets let you apply tailored operational and compliance rules and reconfigure narrow agents without changing general setups. If you already use an enterprise platform like Power Automate or Camunda, the simplest path would be to orchestrate agentic workflows and manage agent instructions using the platform’s low-code tools, just like you do for conventional insurance automation.
Agent trust boundaries
The thing that keeps insurance CTOs awake is not that an agent might be wrong, but that it might go beyond its mandate. You need to enforce trust boundaries through the AI firewall that validates inputs, constrains outputs, and controls which tools agents can call. The AI firewall enforces schema restrictions, preventing agents from issuing free-form instructions that might trigger unintended operations. It blocks unauthorized tool use, so, for example, an investigation agent cannot suddenly call payment APIs. It also catches prompt manipulations and injection attempts, sanitizes claimant submissions, and enforces filters that prevent data leakage.
Cloud-native firewalls available with services like AWS Bedrock Guardrails and Azure AI Safety are a good starting point. However, I recommend supplementing them with custom prompt validators and JSON schemas so that your internal tools execute only when agent requests are fully aligned with your proprietary operating policies.
Explainability and traceability of agent logic
An agent-produced score alone is surely not enough for claims fraud. If a claimant or a regulator challenges a decision, the insurer must be able to demonstrate every logic move, rule, policy, and tool that contributed to that decision. You therefore need full traceability of the agent logic and the components that affected the outcome.
Engineers at ScienceSoft design agentic AI solutions that retain the full history of prompts, agent configurations, and operating rules, and log every action taken by agents in a tamper-evident ledger. In AWS-based architectures, we use S3 Object Lock for immutable recordkeeping and change control. When agents and orchestrators are instrumented to emit traces, logs, and metrics, tools such as CloudWatch, Langfuse, and OpenTelemetry enable teams to reconstruct and audit end-to-end multi-agent workflows. This includes which agent/version ran each step, what tools and data were accessed (with redaction), the intermediate outputs produced, and how the orchestrator routed and combined results.
AI explainability tools can help achieve the granular transparency of agentic logic. Dedicated services like Amazon SageMaker Clarify and all-in-one observability suites like LangSmith let you trace agentic logic and expose model-level explanations with references to source content, claims rule hits, graph paths, and model feature importance. The retrieval augmented generation (RAG) engine supplies the exact policy and claim passages the agent reasons over; observability tools then record and surface those sources for audit.
Agent behavior oversight
LLMOps dashboards give you an exhaustive picture of AI model performance, but agentic fraud detection solutions also need dedicated tools for agent behavior monitoring. Unusual policy read volumes, odd tool call sequences, and evidence retrieval spikes often indicate agent accuracy drifts and attempts to misuse the system. You need to capture those early so that engineering and security teams can intervene proactively.
The observability tools I mentioned above fit well to monitor real-time metrics across agentic tool-use patterns, query sizes, and retrieval outliers. Consider integrating the agentic solution with your SIEM tools: this way, suspicious patterns feed directly to the security track. One more smart practice is to watch for volatility in actual fraud detection rates. Spikes in false positives and false negatives can point to input data quality degradation and agentic data processing issues.
Data security and compliance
At ScienceSoft, we treat encryption as the foundational data security measure for agentic fraud detection solutions. The minimal set of “to-dos” for insurers is to apply transport encryption for API calls, key-based encryption for insurance data in transit and at rest, field-level encryption for regulated data (PCI, GLBA), and tokenization of sensitive identifiers.
Another essential step is ensuring that proprietary data never leaves the insurer’s virtual environment. Model inference must run through private endpoints isolated from the public internet. We achieve this through cloud-native private link integrations, restricted VPC routing, and explicit endpoint policies that block external traffic by design. Global carriers will need to extend controls with data residency rules so a case is always processed in the geography where it legally belongs and in compliance with region-specific data privacy regulations (e.g., an agent working on EU claims won’t be able to access U.S.-hosted data).
You also need to protect the agentic solution itself. For example, in the reference blueprint, I show Amazon’s cross-cutting tool stack for an AWS-hosted agentic solution: threat detection (GuardDuty), vulnerability management (AWS Inspector), data security intelligence (Macie), and unified security and compliance management (AWS Security Hub).
With these agentic AI safeguards working together, SIU gets accurate and fair investigation, adjusters — defensible claim recommendations, security teams — minimized risk radius, and engineers — governance facts that stand up to regulation.
Agent Deployment Realities: Questions U.S. Insurance Leaders Ask
After we presented the fraud detection agent at the Insurance Transformation Summit, most follow-up questions clustered around what it actually takes to get AI agents into production without disrupting claims workflows, rebuilding current systems, and breaking budgets. Here, I address the three most frequent questions from insurance technology and business leaders.
What tooling ensures the fastest agent launch and payback?
My advice for the first agentic AI deployment is to use managed services where possible. For example, specialized frameworks like LangGraph and LangChain and cloud provider services (Microsoft’s Azure AI Foundry and AWS’s Amazon Bedrock AgentCore) let you quickly roll out proprietary AI agents for specific fraud detection tasks. These services cover comprehensive toolkits for multi-agent orchestration, observability, and AI firewalling, giving you a fast path to launch with minimal implementation overhead.
Another advantage is that managed agent engineering services typically come with connectors to many leading LLMs, giving insurers access to the best-performing models without having to set up multiple individual APIs.
How do we integrate agentic AI with our legacy systems?
At ScienceSoft, we use event-driven integration as the backbone. In this pattern, claims events captured in the claim software (think a FNOL intake or an evidence upload) trigger the agent workflow in the agentic solution. When the workflow finishes, the orchestrator writes the investigation brief and referral back into the claims system through an abstraction layer (APIs or custom connectors). With such a design, agentic AI has clean entry and exit points and doesn’t require any rebuilds of older cores or homegrown claims platforms.
If an insurer doesn’t have an event bus, we start with something as simple as a webhook. For more mature stacks, we apply Kafka topics and EventBridge buses. ACORD messages and EDI transactions for health claims slot naturally into this pattern, and idempotent adapters ensure an agent never writes the same update twice.
Before integration go-live, I recommend that you use a shadow mode, where agentic fraud detection runs in parallel with human investigation, and the teams explicitly compare agent outputs to the insights produced by SIU. Once the business is comfortable with AI fraud detection relevance, you can move to blue-green rollouts and phased activation by insurance line.
How do we prepare our data for an AI agent launch?
First, clean up insurance data identifiers. You need a single source of truth for employees, policies, insureds, assets, and providers. Normalize IDs, standardize billing details, and tokenize contact info so agents can link entities consistently. Without this, agentic search just won’t surface data, dependencies, and patterns that matter for fraud detection effectively.
Second, implement automated data validation tools. At ScienceSoft, we recently used AWS Glue Data Quality and Azure Data Quality for that, but there are other robust options as well. You need this to catch and fix inaccuracies in external data feeds before an agent sees them. Proactive data checks guard against a common failure mode: an agent making the “wrong” decision because of a mislabeled claim field, a wrong date format, or overlooked evidence corruption.
Next, build claims evidence custody. Documents, photos, videos, and call recordings need to live in a secure object store (e.g., Amazon S3 / NAS) so nothing can be altered or lost. Embeddings, structured extractions, and fraud risk scores produced by the AI agents should go into a feature store to keep agent outputs traceable for internal and regulatory reviews.
Parallel to this, set up RAG components — data vectorization pipelines, a vector index, and a graph database. These will enable your fraud detection AI agents to retrieve and interpret unstructured contextual data like investigation policies, claim evidence, and compliance instructions. The investment pays off at scale: you can further reuse these components for any LLM-based solutions that require access to your proprietary data.

Insurance AI Software Engineering
A dedicated session with ScienceSoft’s insurance AI experts yields a practical roadmap covering priority use cases, compliance checkpoints, integration steps, and time-budget estimates for fraud detection agents.
Book a practical expert session

